Cache —— 替换算法和写策略
本文共 1254 字,大约阅读时间需要 4 分钟。
一、替换算法
在采用全相联映射和组相联映射方式时,从主存向 Cache 传送一个新块,当 Cache 中的空间被占满时,就需要使用替换算法置换 Cache行。而采用直接映射则不需要考虑替换算法。
- 随机算法(RAND):随机地确定替换的Cache块。它的实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低。
- 先进先出算法(FIFO):选择最早调入的行进行替换。它比较容易实现,但也没有依据程序访问的局部性原理,可能会把一些需要经常使用的程序块(如循环程序)也作为最早进入Cache的块替换掉。
- 近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,平均命中率要比FIFO要高,是堆栈类算法。LRU算法对每行设置一个计数器,Cache每命中一次,命中行计数器清0,而其他各行计数器均加1,需要替换时比较各特定行的计数值,将计数值最大的行换出。
- 最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从0开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。
在二路组相联映射中采用 FIFO 替换算法:

在二路组相联映射中采用 LRU 替换算法:

二、Cache 写策略
因为 Cache 中的内容是主存块副本,当对 Cache 中的内容进行更新时,就需要选用写操作策略使得 Cache 内容和主存内容保持一致。此时分为两种情况。
Cache 写命中的处理方法
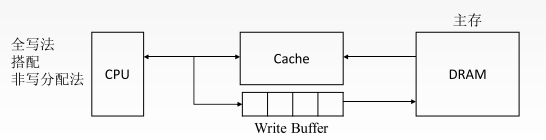
(1)全写法
当 CPU 对 Cache 写命中时,必须把数据同时写入 Cache 和主存。当某一块需要替换时,不必把这一块写回主存,用新调入的块直接覆盖即可。
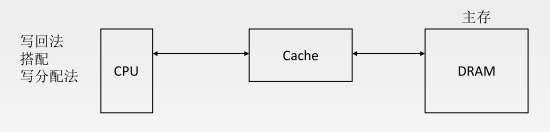
(2)写回法
当 CPU 对 Cache 写命中时,只需改 Cache 的内容,而不立即写入主存,只有当此块被换出时才写回主存。采用这种策略时,每个 Cache 行必须设置一个标志位(脏位),以反映此块是否被 CPU 修改过。
Cache 写未命中的处理方法
(1)写分配法
加载主存中的块到 Cache 中,然后更新这个 Cache 块。写分配法通常与写回法一起使用。(更新 Cahce )
(2)非写分配法
只写入主存,不进行调块。非写分配法通常与全写法一起使用。(更新主存)
含有两级 Cache 的系统
L1 Cache 对 L2 Cache 使用全写法,L2 Cache 对主存使用写回法,由于 L2 Cache 的存在,其访问速度大于主存,因此避免了因频繁写时造成的写缓冲饱和和溢出。

转载地址:http://fgkii.baihongyu.com/
你可能感兴趣的文章
mapReduce(3)---入门示例WordCount
查看>>
hbase(3)---shell操作
查看>>
hbase(1)---概述
查看>>
hbase(5)---API示例
查看>>
SSM-CRUD(1)---环境搭建
查看>>
SSM-CRUD(2)---查询
查看>>
SSM-CRUD (3)---查询功能改造
查看>>
Nginx(2)---安装与启动
查看>>
springBoot(5)---整合servlet、Filter、Listener
查看>>
C++ 模板类型参数
查看>>
C++ 非类型模版参数
查看>>
设计模式 依赖倒转原则 & 里氏代换原则
查看>>
DirectX11 光照
查看>>
图形学 图形渲染管线
查看>>
DirectX11 计时和动画
查看>>
DirectX11 光照与材质的相互作用
查看>>
DirectX11 法线向量
查看>>
DirectX11 兰伯特余弦定理(Lambert)
查看>>
DirectX11 漫反射光
查看>>
DirectX11 环境光
查看>>